I stored the same text file in various encodings with notepad (a fine tool for unicode diagnostics).
I read in those files in python, as plain 8-bit streams. No surprises there:
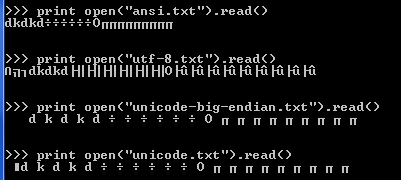
...
Of course it happened again: program works okay, unit-tests suck
and must be debugged.
At this point, I have my unicoder (18:36), and the unit-tests show that
it works.