/
unicoding
unicoding
- reinhard reinhard (Unlicensed)
Owned by reinhard reinhard (Unlicensed)
Last updated: Apr 13, 2010Version comment
I stored the same text file in various encodings with notepad (a fine tool for unicode diagnostics). I read in those files in python, as plain 8-bit streams. No surprises there:
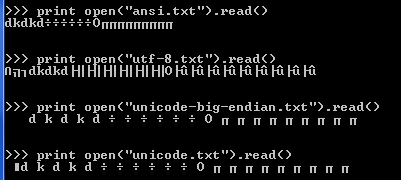
Here is a breakdown of the BOMs (http://en.wikipedia.org/wiki/Byte-order_mark):
UTF-8 |
EF BB BF |
UTF-16 BE ("unicode big endian") |
FE FF |
UTF-16 LE ("unicode") |
FF FE |
decode works as expected:

Of course it happened again: program works okay, unit-tests suck and must be debugged.
At this point, I have my unicoder (18:36), and the unit-tests show that it works.
, multiple selections available,