ASP.NET for people who did not bother until now
With substantial input from Martin Schwarzbauer.
A quick patch for the impatient ASP.NET neophyte
This section is a brief introduction to the most important concepts of ASP.NET. Large volumes have been written about ASP.NET, and most of the more comprehensive books can seriously hurt you if they drop on your foot. However, for understanding, using and appreciating re-motions's essential features, you don't need to be an ASP.NET expert. This small primer can't do the complexity and sophistication of ASP.NET justice; it is intended as a band-aid for impatient readers who want to go on with the re-call section in the phone-book tutorial without marching through an entire ASP.NET-book first. Despite the fact that uigen.exe generates an ASP.NET-application, most of the topics discussed in this section are not really required before the chapter on re-call in the PhoneBook tutorial.
ASP.NET
A major challenge in web-programming on the bare metal (i.e. without ASP.NET or a similar framework) is that the web was not intended to be an application platform. The web was constructed more like a file system for the global distribution of "content" (text and images). You give your browser an URL, the browser gets you the file behind that URL. The server actually delivering a page forgets you and your browser immediately after the transmission. The following two characteristics of this simple technology facilitated the tremendous success of the web:
- URLs are supposed to uniquely identify a particular page (or other file) on the entire web (or, by extension, an intranet).
- The web is stateless, i.e. the serving computer can't remember anything for you. This keeps things simple and scalable.
What's good for serving content is bad for programming applications, however:
- URLs are a lousy medium for telling an application what to do next.
- An application server not remembering anything is usually not very useful.
As clever programmers figured out quickly in the 1990s, you CAN build web-applications on top of the infrastructure that browsers and HTTP give you, it is just much harder than
building a regular application that runs locally on a computer or as client-server. The problem is that the web as application platform does not lend itself well to the style of programming developers of GUI-applications have invented and refined over the previous two decades – based on objects within objects, events and event-handlers.
ASP.NET (and similar competing products) tries to alleviate this discrepancy by dressing up the browser/HTTP foundation of the web in such a fashion that it looks more like regular object-oriented GUI-programming, complete with objects which remember their state from page request to page request, events and event-handlers belonging to certain objects.
This convenience requires that an ASP.NET page (an .aspx page) is not just static content. It is a computer program for control elements like text-boxes, buttons or drop-down menus. These elements are .NET objects, complete with properties and methods. What's more, the entire page, even the entire web-application, is a .NET object. It is not the ASP.NET "page", i.e. the static content that is sent to the browser, it is the HTML the page/program/object generates when running on the server. A browser requesting an ASP.NET-page causes that page/program/object to run on the server and send back what this run produces as output.
The ASP.NET markup for declaring and laying out the controls and content of a page closely resembles HTML and is stored in .aspx files (or .ascx files for assembling controls). The code governing the controls', page's and application's behavior is stored in so-called "code-behind" declarations, or code-behind files. In ASP.NET 2.0, code-behind code can be stored in separate files, which by convention have the same name as the .aspx-files they belong to. Example: the code-behind for Foo.aspx is put in Foo.aspx.cs (or Foo.aspx.vb for Visual Basic-programmers).
Here is an annotated diagram to illustrate the concept of HTML-generation (the "rendering") by an .aspx and .aspx.cs-program:
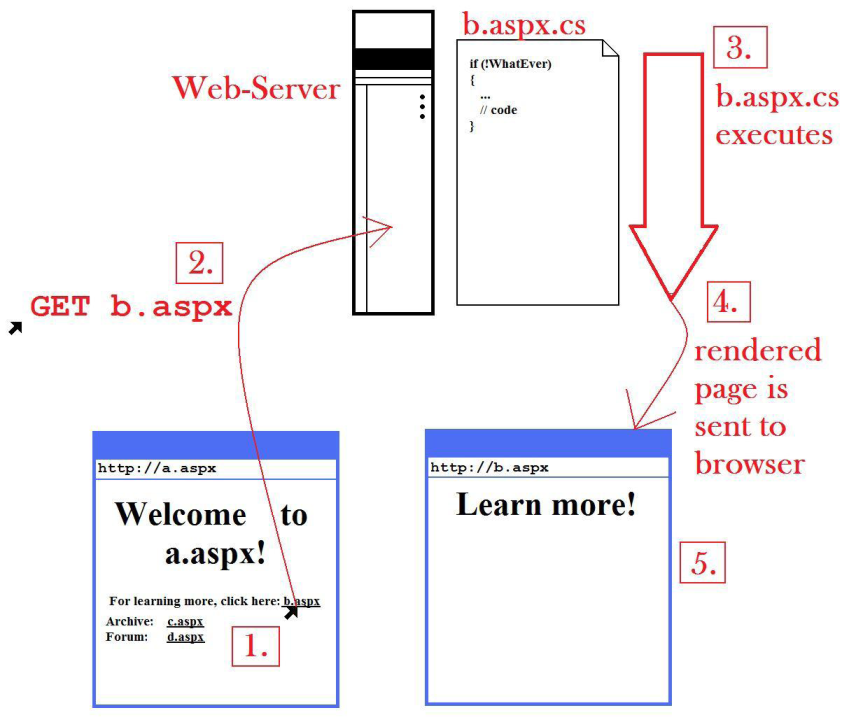
- As we see in the picture, the browser is showing an
.aspxpage nameda.aspx. What you can't see is that the HTML the user has in her browser has been generated by that a.aspx page and its associated code-behind ina.apsx.cs, because that has happened in the recent past. The diagram begins with the user clicking on the link for another.aspxpage –b.aspx. - The browser sends the request for
b.aspxto the web-server. - The web-server executes
b.aspx, or, the code-behind inb.aspx.cs, what renders the page. - The rendered page (i.e. a mix of HTML and, most likely, javascript) is sent to the browser.
- The browser displays the HTML (and javascript) for
b.aspx.
Things are not quite as simple when a user manipulates a control element. In this case, the browser sends additional information about the contents of the page and its controls (view state) and the manipulated control. The latter is used by ASP.NET to raise a corresponding event that can be handled by a method (event handler) provided by the application developer. For example, when a user fills in a form and clicks the submit button, the filled-in values are sent to the server along with the information that the submit button has been clicked; ASP.NET then calls the event handler that is associated with the button (e.g. SubmitButton_Click in TestForm.aspx.cs). The form information is put into the ViewState object so that the event handler (and other server-side code) can access it and store it in a database, for example.
In addition the view state, which makes client-side information available on the server (and allows the server to control the state of web controls at the time of rendering), ASP.NET provides "session state" that stores information associated with an ongoing interaction between browser and web server on the server, so that the server can follow up on a conversation with a particular client when it sends another page request. The following section elaborates on session state.
To make the illusion of programming a regular client-server application complete, ASP.NET provides several means of storing an application's "session" state (its "variables") from page
request to page request, but they fall into two categories:
- the data is stored in the web-browser
- the data is stored on the web-server
In order to discuss these options more verbosely, let's look at what a web-application has to remember actually.
Storing session state
In agreement with the concept of statelessness, the web-server is not interested in what order pages are viewed, because it has forgotten about your request for a certain page right after serving it. This is anti-helpful for web-applications. For exmaple, our phone-book application must not forget that it served you an edit form for a particular Person object, because it is part of a unit of work.
For this reason, the concept of a session has been introduced to the web. A session is an ongoing conversation between the web-browser and the server. In the case of an ASP.NET web application, the session lasts from the first page request to closing the browser. (What's more, ASP.NET sessions fail with a timeout if you don't do anything for a while.) What makes sessions possible is session IDs, i.e. unique identifiers generated by the web-server and sent to the client, which has to send it back with each request. Such an ID is also called a cookie. It is like getting a receipt (essentially an identifier, like a cookie) when checking in your coat at the laundry. The receipt, like the cookie, identifies you and your coat. The laundry-server uses that ID to identify its business with you.
If you go to another page to edit data in that Person's Location, the server must know that it is you and your session who returns to the server with that Person object. The server must know this for several reasons, but the most important one is that re-store must open a sub-transaction for Location on top of the client-transaction accommodating the Person data. To this end alone, the web-server must keep track of you and your unit of work that (by definition) might span multiple pages sharing data, so that it can always match you and your subsequent request to precisely your data ("state"). Keep in mind that a web-application serves multiple concurrent users.
The data (the coat, in the laundry example) shared by these pages is, by definition, the session state. Since the web-boom of the nineties, the canonical example for a session is that of an online-shopping session and the associated shopping-cart: Your trip to http://amazon.com (for example) involves multiple pages – searching for titles, browsing results, adding books to your shopping cart. The session lasts from the point in time when you add your first book until you roll your shopping cart to the virtual check-out and have your order cleared with your credit-card company. In this example, the session data is the list of your new soon-to-be-shipped books piling up in the shopping cart.
A cookie can either store those items itself, or it only stores the session ID while the associated state is kept on the server. In either case, the web server has to start handling a request by setting up the state it had after the last request - either from the cookie or from the session state associated with the received session ID.
The first approach sticks to the stateless nature of the web and frees the server from any responsibility of keeping track of its conversations, which means that having multiple servers to handle requests is easy, as they do not have to synchronize anything. However, as cookies become larger due to ever more variables needed for ever more complex applications, cookies use a lot of bandwidth. What is more, they are not secure: anyone can edit cookies on their computer with a simple text editor, Javascript can access cookies directly, and so sensitive information does not have to be encrypted and decrypted once, but every time a request is received or sent.
In the case where all the items in your shopping cart are stored in your browser, this information must be sent over the wire in its entirety - in both directions, mind you. After all, the new, updated version of the shopping cart must be remembered by your browser after the request. A more compact version of this scheme is to store this data on the server and communicate only a reference to that data between the browser and the server. This has the disadvantage that statelessness - a major factor in the web's success - goes out the window. Very large web-sites like http://amazon.com must use multiple webservers for handling the requests from hundreds of concurrently operating shoppers. This is easy if the entire shopping cart is sent between browsers and servers, albeit it comes at a price: it takes time and bandwidth sending entire shopping carts over the wire.
You can save time and bandwidth by exchanging only references to data on a particular server. What if your second request, with two books already in your shopping cart, is served by a different server than the first request? How does the second server get the data stored on the first server? Or, how can you make sure that the load balancer, the computer spreading requests from browsers evenly over available servers, always directs your requests in the session to the same server? This is where scaling problems of "stateful" applications enter the picture. (ASP.NET dodges this scaling-problem entirely by supporting one (and only one) state server, i.e. a dedicated, central computer that all web-servers ask for storing and retrieving the state for a given session.)
Cookies are not the only medium for storing data in the browser. Another method is "hidden fields" - web controls that the browser does not display, but which otherwise act like a textbox, for example: it has a name and a string value, is part of a form and is therefore sent when the form is submitted. The difference to cookies is that cookies are transferred in the HTTP header, not the HTML document, while hidden fields are form controls embedded in an HTML document whose contents are sent as part of the view state. Independent from the method, the idea is the same: the state of the conversation between client and server is stored on the client side and sent back to the server with each request. Both methods can be used to store extensive state on the client or only a session ID (and perhaps a few variables) that is used by the server to load the state it manages itself for that particular session.
Independently from the medium of storage, the key ideas are always the same:
- send all the session data back and forth between browser and server (scales well, takes bandwidth and extra effort to encode and decode the data)
- send only a reference to the data back and forth between browser and server (takes very little bandwidth and effort, but you give up the advantages of statelessness)
re-call, re-motion's web execution engine, inherits from ASP.NET the ability to store state information in a database, a state-server, in the process (i.e. in memory) or in the browser itself. In practice, even a mix of these methods can be used.
Postbacks, Respond.Redirect and Server.Transfer
A central concept in ASP.NET is that of the postback. The term simply means that form data is "posted back" to the same page/code that generated the form. Remember that, in ASP.NET, web-pages are actually computer programs. The page/code that generated the form to be filled in is also the page/code that processes the filled in form. In ASP.NET-jargon, the page/code is "posted back" to the server by the browser, potentially over and over again. Useful applications can be built using just a single page. A good example is a search engine. Here is a comic of an ASP.NET search-engine implementation:
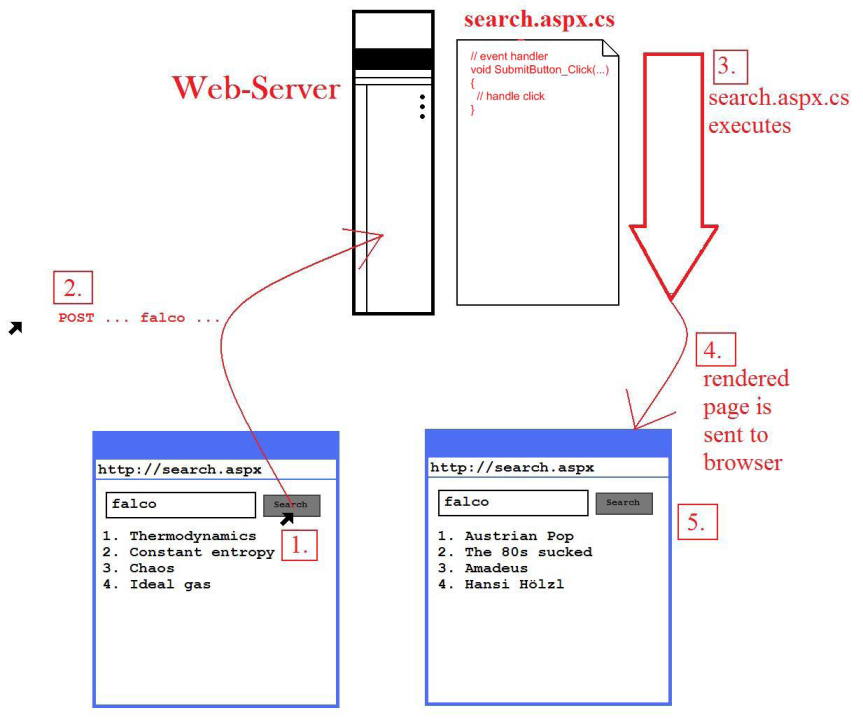
What happened before: the user has submitted a query for the term "entropy" and got four hits related to the topic. The resulting hit-page has been generated by search.aspx. Now, and this is what you see in the left browser-pricture, the user has changed her mind and wants to search for the term "Falco" (one of the few Austrian pop-stars ever to hit the American Top 40, ca. 1981). At this step, the user clicks Search to submit the "Falco" query.
The page, (or actually the form's data, i.e. "falco") is posted back to the web-server, or better: the search.aspx-page.
The web-server runs search.aspx again, or, to be more exact, the event-handler for the Search-button click runs again. So this click causes the evaluation of the "falco" term and causes a database query to the searched repository.
The text-box for entering a new term and the hits from the search are wrapped up in HTML = the page with the search results is rendered by search.aspx and its code-behind.
The user finds the newly rendered page in her browser, complete with a text-box and the four hits unearthed by the query. The user is ready for the next query, and round and round it goes.
The beauty of this scheme is that the code to render the form and all the code to handle data entered into the form are wrapped up into one neat package (a page object, that is). However, here we face a problem: What if we want to render a different page in response to a request? We already know that by rendering links, the client can navigate from one page to another by clicking the link, but what if the server-side code determines that another page should get control of the request and handle it? Two techniques exist, named after their corresponding API-calls:
Response.RedirectServer.Transfer
To see how each of them works, let's use a detail from another web-site – entering personal data when registering at a dating web-site. We use two pages, boringly called first.aspx and next.aspx.
first.aspxis a form for entering a nickname, gender, sign of zodiac and agenext.aspxis the next form, asking for favorite pastimes, so that the web-site can match-make the user with other users with overlapping interests.
For this web-site to work, the server must cause a transition from first.aspx to next.aspx as soon as the user has submit first.aspx (and the input could be validated). Just as the name suggests, Response.Redirect achieves this by sending the browser a redirection response, telling it to request the desired page – a fairly conventional technique most web-programmers know.
Server.Transfer is more sophisticated: The server pretends that the next page (i.e. the desired page) is the same as the one before, just as in our search-engine example. In reality, however, not the code-behind for the page is run to re-render the page. It's the code-behind for the next page that is run. Here are two diagrams to illustrate the concepts – one for Response.Redirect and one for Server.Transfer.
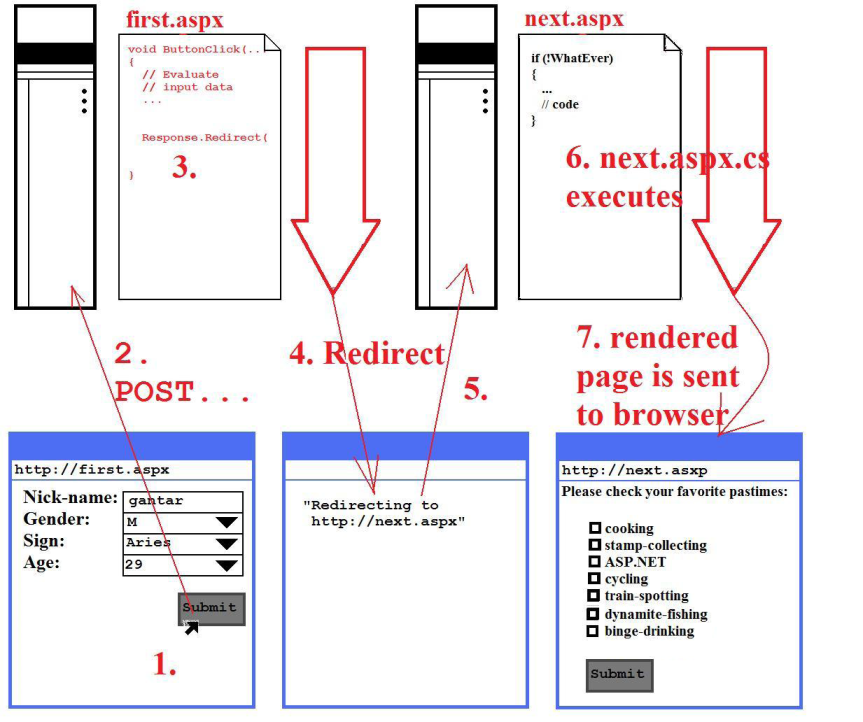
- The user (in this case the author) has entered his first installment of personal data and lied about his age (of course!) He clicks the Submit button to post that data to the
first.aspxpage/program. - The data is posted.
first.aspxexecutes, or better: the event-handler for the Submit-button. This event-handler finds this data to be in good working condition and therefore initiates the display of thenext.aspxpage by executing aResponse.Redirecttonext.aspx.- The redirect is solicited from the browser with a 301 http-packet (wikipedia)
- The browser does as told by the server and requests
next.aspx - The server merrily obliges (after all, he came on to the browser first) and runs
next.aspx, just as if it was the browser's original idea. next.aspx executes, thus rendering the pastime-page for the author's browser. - The author finds the newly rendered
next.aspxform.
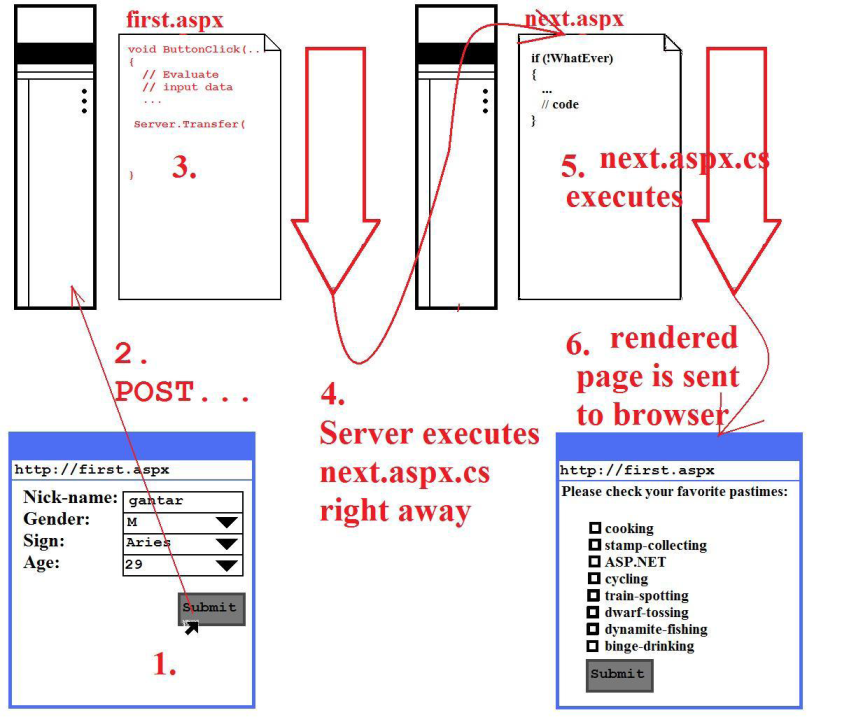
- The author has entered his first installment of personal data and lied about his age (again!)
- The data is posted.
- first.aspx executes, or better: the event-handler for the Submit-button. This event-handler finds this data to be in good working condition and therefore initiates the display of the next.aspx page by executing a
Server.Transfer. - next.aspx is executed on the server, rendering the html for the next.aspx page.
- The rendered page is sent to the browser.
Note that the URL displayed in the browser still is http://first.aspx. This is not a mistake by the author who drew the picture. The browser did a postback to first.aspx and thinks it got back the rendition of first.aspx's code-behind. The browser cannot know that, meanwhile, the server has sneaked the execution of another page into the browser's request.
Compared to Response.Redirect, Server.Transfer has one big advantage and one disadvantage. The advantage is that it takes one round-trip less for the transition to the next page; the disadvantage is that an URL does not uniquely identify a particular page. The disadvantage might look minor to you, but often the "U" in "URL" - having a unique identification for a page - is more important than performance. In its pure form, the URL is required to specify even which domain object(s) is/are displayed in the browser, so that the server can completely reconstruct what is seen in the browser from the URL alone. re-motion supports this behavior, but not by default.